
Import and Search Capsule
Overview
The Import and Search capsule template allows you to construct capsules that allow users to query underlying data tables through natural language. The queries can be relational, linking a main data table to supplementary data tables: a movie information capsule, for instance, could have a table of movies and a table of actors, letting you train it on such utterances as:
- "Show all movies."
- "What movies are playing starring Chris Evans?"
Tables are imported into the Import and Search template builder in CSV (comma-separated values) format. The template will create concepts named after the table column headers and infer types based on the values. That's not all, though: the Import and Search template also infers relationships between tables based on column names and data.
In the example for the movie information capsule, a movies table might have the following structure:
| id | name | posterImage | actors | description |
|---|---|---|---|---|
| 429617 | Spider-Man: Far from Home | 429617.jpg | "1136406,131,505710" | "Peter Parker and his friends ..." |
| 420818 | The Lion King | 420818.jpg | "119589,14386,15152" | "Simba idolises his father, King Mufasa ..." |
| 559969 | El Camino: A Breaking Bad Movie | 559969.jpg | "84497,88124,82945" | "In the wake of his dramatic escape ..." |
And an actors table might look like this:
| actorId | actorName | profileImage |
|---|---|---|
| 1136406 | Tom Holland | 1136406.jpg |
| 131 | Jake Gyllenhaal | 131.jpg |
| 505710 | Zendaya | 505710.jpg |
The Import and Search template can infer that the actors column in the movies table refers to the actors table. Since movies have multiple actors, this column contains array values linking to the actors by ID.
The actual "Movie Agent" sample data is generated from The Movie DB, and can be regenerated by a Python script included in the sample repository. The URLs for poster and profile images in the actual sample data are complete, working URLs; they're abbreviated here in the documentation for readability.
Capsule Type
The Import and Search template can create two types of capsules:
- Search is for querying information in the CSV database, such as the Movie Agent capsule.
- Transactional adds "shopping cart" functionality, letting users add items from result pages to a cart to perform a transaction using a search result. Each main concept type in a transactional capsule must have a Price column. See Transactional Capsules for more information.
Table Format
There are conventions you must follow when creating CSV files for the Import and Search template, as well some special syntax you can use to tweak how Bixby Developer Studio maps the table content to concepts.
General
- The CSV files must include a header row.
- The CSV files must have values separated with commas, not tabs or any other separator value.
- Empty cells can be included on non-header rows.
- The first column of primitive type
name, or the first column in the table if nonamecolumn is found, is treated as the row's description: for example, thenamecolumn in themoviestable above, and theactorNamein theactorstable.
The movies table above looks like this in CSV form:
id,name,posterImage,*actors*,-description
429617,Spider-Man: Far from Home,https://image.tmdb.org/429617.jpg,"1136406,131,505710","Peter Parker and his friends ..."
420818,The Lion King,420818.jpg,"119589,14386,15152","Simba idolises his father, King Mufasa ..."
559969,El Camino: A Breaking Bad Movie,559969.jpg,"84497,88124,82945","In the wake of his dramatic escape ..."Mapping Columns to Concepts
First, here are some general guidelines:
- It's best practice to give the columns names that describe their concepts:
actorNameinstead of justName. - A column that ends in
Id(or just namedid) will be assumed to be a unique identifier for the column. It's recommended all tables that describe single concepts, likeactors, have ID columns; tables that describe relationships, likemovies, should have columns that refer to ID columns in other tables. - Column names should be unique across all CSV files.
To show how column names and data are used to derive column types, take the following example of a Hotel concept:
HotelName,Website,*Amenities*,Stars,Reviews,City,Price,CheckinTime
The Peninsula,https://hotelpeninsula.com/,"pool,jacuzzi",4.0,164,Paris,$400,11:00am
Regent Berlin,https://regentberlin.com/,"wifi,pets",5.0,463,Berlin,$300,11:30am
Brown's Hotel,https://brownshotel.com/,wifi,4.5,268,London,$350,11:00am- A column that ends in
Name(or is just namedname) will be given anameprimitive type, likeHotelNameabove. - A column that ends in
TextorDescription(or is just namedtextordescription) will be given atextprimitive type. - A column named
pricewith numeric values will be mapped toviv.money.Currency. - A column with only integer values, like
Reviewsabove, will be mapped toIntegerprimitives. - A column with at least one decimal value, like
Starsabove, will be mapped toDecimalprimitives. - A column ending with (or named)
City(as above),Country, orState, will be mapped toviv.geo.SearchRegion. - A column whose name is or contains
geopoint,geo_point,coords,coordinates,latlong, orlat_longwill be mapped toviv.geo.GeoPoint. Values in aGeoPointcolumn must be latitude/longitude pairs inside double quotes and separated with a comma:"37.87, -119.54". - A column with date values will be mapped to
viv.time.Date. - A column with time values will be mapped to
viv.time.DetachedTime, likeCheckinTimeabove. - Columns with URL values will be mapped as follows:
- A column with URL values that end in
jpg,jpeg,png, orgifwill be mapped toImage. - A column with URL values that end in
avi,wmv,flv,3gp,mp4, ormpgwill be mapped toVideo.- If the video URLs in a column have a domain of
youtube.comoryoutu.be, the column will be mapped to theYouTubetype. - If the video URLs in a column have a domain of
vimeo.com, the column will be mapped to theVimeotype.
- If the video URLs in a column have a domain of
- A column with URL values that do not appear to be images or videos, like
Websiteabove, will be mapped toUrl.
- A column with URL values that end in
- If two or more columns in the main table link to the same column of another table, they will be given a role of the matching concept. For example, a table of basketball games could be linked to a team table with
HomeTeamandAwayTeamcolumns; the generatedHomeTeamandAwayTeamconcepts would have roles ofTeam.
Cardinality
By default, properties in generated models are given default cardinality of min (Optional) and max (One).
You can add a prefix character to column names to control input cardinality:
!:min (Required) max (One)*:min (Optional) max (Many)+:min (Required) max (Many)-: do not add this column as an inputi:: add this column as an input, but exclude it from the generated concept
You can add a suffix character to column names to control output cardinality:
!:min (Required) max (One)*:min (Optional) max (Many)+:min (Required) max (Many)-: do not add this column as an output property
In the hotel example, the Amenities column has a min (Optional) max (Many) cardinality, and is prefixed with *. It also has array values in that column, which means it requires an output cardinality of max (Many), and thus is suffixed with * as well.
HotelName,Website,*Amenities*,Stars,Reviews,City,Price,CheckinTimeYou could make HotelName a required output by appending a ! to its column name:
HotelName!,Website,*Amenities*,Stars,Reviews,City,Price,CheckinTimeAnd you could make all the properties required by prepending ! to the single-value ones and changing the * prefix to + for Amenities:
!HotelName,!Website,+Amenities*,!Stars,!Reviews,!City,!Price,!CheckinTimeIn practice, only inputs that are truly necessary for every search query should be set to a min (Required) input cardinality.
Array Values
A cell can contain comma-separated array values, like in the following table:
| HotelName | Amenities* |
|---|---|
| The Peninsula | "pool,jacuzzi" |
| Regent Berlin | "wifi,pets" |
| Brown's Hotel | wifi |
Since they contain commas, array values must be quoted in the actual CSV file. See the example in Cardinality above.
Columns with array values must be suffixed with * or + to set their cardinality to max (Many). Otherwise they will default to Max (One), and the whole quotes text will be interpreted as one value, such as the actual text "pool,jacuzzi", rather than as multiple values!
GeoPoints and Maps
If you have a column that's mapped to GeoPoints and contains latitude/longitude coordinates, the details view for those entries will include a map. Tapping on the map, or asking Bixby to "get directions", will open Google Maps with the appropriate point selected.
Values in a GeoPoint column must be latitude/longitude pairs inside double quotes and separated with a comma. For example:
ParkName,State,Country,Image,GeoCoordinates
Joshua Tree,California,USA,https://example.com/images/Joshua_Tree.jpg,"33.881866, 115.900650"
Redwood,California,USA,https://example.com/images/Redwood_National_Park.jpg,"41.213181, -124.004631"
Sequoia,California,USA,https://example.com/images/Giant_Forest.jpg,"36.486366, -118.565750"
Yosemite,California,USA,https://example.com/images/YosemitePark2_amk.jpg,"37.865101, -119.538330"Input Filters
Depending on your data sets, your capsule might need to handle queries that allow filtering based on values, similar to an SQL WHERE clause:
- "Show me shoes between 50 and 100 dollars"
- "Show me hotels of 3 stars or higher"
- "Show me rooms with 2 beds"
The Import and Search capsule template can generate models that handle these cases for you by using filters.
To define a filter, append a [filter] tag to a column heading, such as:
HotelId,HotelName,RoomPrice[filter=min:max],Beds[filter=eq]Use [filter=filter1:filter2:...] to specify filtering operations that are allowed on the column. The available operations are:
min: allow specifying a minimum value.max: allow specifying a maximum value.eq: allow specifying an exact value.none: do not allow filtering and do not use this column as an input to the find action.
The available filtering operations are dependent on the column:
datecolumns automatically have filtering operations set up to allow them to be filtered by an exact date or a date interval ("games next week") unless they are filtered withnone.geocolumns (bothGeoPointandSearchRegion) automatically have filtering operations set up to allow them to be filtered by a search region ("parks in California") unless they are filtered withnone.minandmaxfiltering operations are ignored forname,text, andidtypes; onlyeqandnoneare available.- No filtering is available for
image,url,video,youtube, andvimeotypes.
Display Targets
You can control whether the data from a column shows up on summary or detail cards by appending [display=...] to the column name.
HotelId[display=summary],HotelName,RoomPrice,Beds[display=details]summary: the column should only appear in the summary viewdetails: the column should only appear in the details viewnone: the column should not appear on either summary or detail cardssummary:details: the column should appear on both kinds of cards
Note that a summary view is not guaranteed to have enough room to show all columns with a summary display target, as there is limited space available.
If a display target is not specified for a field, the template generator will use internal heuristics to decide which views those values should be displayed in.
Column Labels
Each column can have a label suffix to specify singular and plural forms for that column in the capsule's output language, of the form [label=singular:plural]:
HotelName[label=Hotel],Website,*Amenities[label=Amenity:Amenities],Stars,Reviews,City,Price,CheckinTimeThis label is required for non-English languages. If you supply only one form (as in [label=Hotel]):
- In English, the supplied form will be used as the singular form, and the plural form will be created by adding an "s" ("Hotel" → "Hotels"). For words with plural forms that don't follow this convention ("Candy" → "Candies", not "Candys"), you should explicitly supply both singular and plural forms:
[label=Candy:Candies]. - In all other languages, the supplied form will be used for both singular and plural.
Multiple Directives
If you need to specify multiple directives in brackets, they should appear one after another with no space between the brackets, such as:
HotelName[display=details][label=name]Order is important:
- Input cardinality prefix character (
+,-,*,!) - Column name
- Output cardinality prefix character (
+,-,*,!) - Any bracket directives like
[filter=...],[display=...], and[label=...](these can be in any order)
Transactional Capsules
A Transactional Capsule has all the functionality of a Search capsule, with the addition of shopping cart-style functionality.
- Items found via search can be added to the cart.
- The cart can have items added or deleted, or have the quantity of items in the cart updated.
- The user can confirm an order, completing the transaction.
- A completed transaction can display its order status, progressing from Ordered through Shipped to Delivered.
The generated capsule simulates the post-confirmation order flow; to use the capsule as a real shopping cart, you'll need to modify the generated code to talk to a server.
- To commit an order, modify
CommitOrder.js. The generated code includes apay()function which can be used as a guideline for communicating to a back-end server. Your capsule could also punch out to a client application on the device usingapp-launch. - To track an order status, modify
CheckStatus.js. The generated code simply increments the various order states; real code should contact your service and return a validOrderState. (TheOrderStateis anenumprimitive whose valid symbols areOrdered,Shipped,Delivered, andCancelled.)
Usage
When you start the Import and Search capsule template builder and choose a language for your capsule, you'll be presented with an Import and Search Template Screen.
You should load the main table, such as the games table in the basketball schedule example, first, then load tables that columns in the main table refer to, such as the teams table.
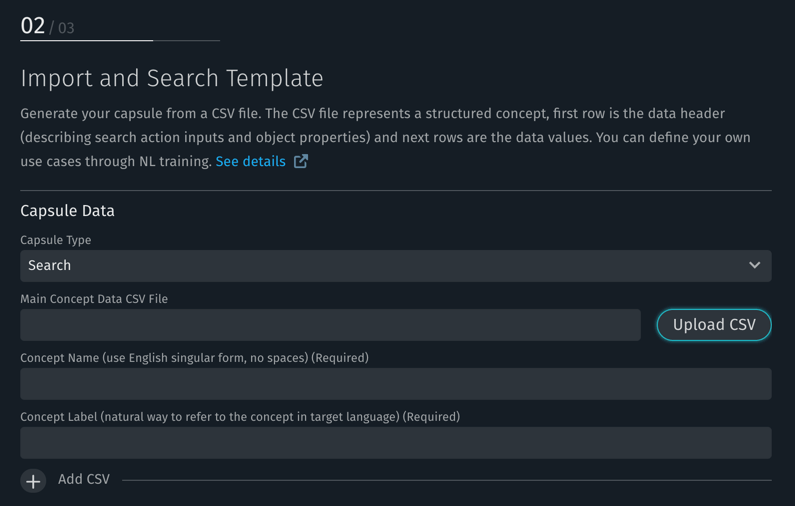
- Select the Capsule Type: Search or Transactional.
- Select the first CSV file (such as
games.csv) by clicking Upload CSV. - Enter a name for the concept that CSV file describes. This name should be in English and have a singular form (such as
Game). - Enter a label for the concept in its target language. This label can contain both singular and plural forms separated by a colon, such as
game:games. If you only specify one form, then in non-English languages, it will be assumed to be both singular and plural; in English, an "s" will be added to the form to make it plural (sogamewill be automatically pluralized togames). - If you have more than one CSV file, click Add CSV and enter information for those files, too.
- When all CSV files are entered, click Next Step.
- Enter a capsule ID (such as
playground.nbaSchedules). - Choose a folder to save the new capsule in, or accept the default.
- Click Generate Capsule.
After the capsule is generated, Bixby Studio opens the README file for your newly created capsule, with information about what models and basic training it's generated, along with some advice about next steps.
Sample Import Data
You can download sample CSV files for a variety of possible search capsules, including the NBA teams and schedules example, at the Bixby Developers GitHub repository.
https://github.com/bixbydevelopers/sample-template-import-data